You might not need Fivetran and dbt, just one platform that does both, with the AI built in
June 11, 2026
— min read
Henry Owen
Product Marketing Manger
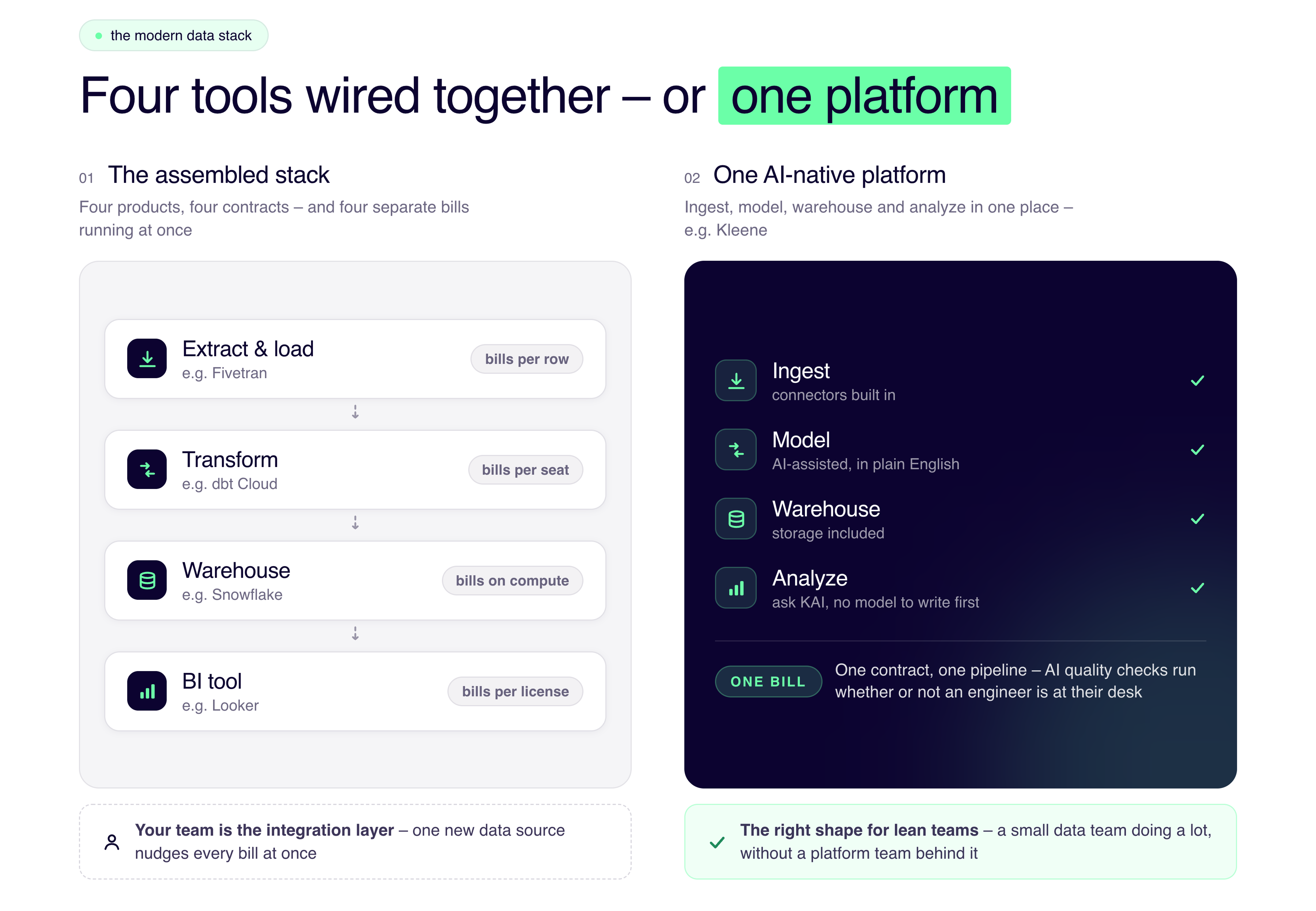
The "modern data stack" most teams were told to build is, for a lot of mid-market companies, more overcomplicated than the job it requires. Fivetran moves your data, dbt models it, a BI tool visualizes it, an orchestrator schedules it, and then someone spends time keeping the whole arrangement running smoothly.
It works, and we're not going to pretend otherwise. Fivetran and dbt are excellent at their jobs, and there's a reason they each have thousands of happy customers. But "excellent at one job" and "the right setup for a lean headcount" aren't always the same sentence. And the questions buyers are asking now make the gap pretty clear.
What people are searching for
We track how AI assistants answer buying questions in our space (yes, that's a slightly recursive thing for a data company to do). When someone asks ChatGPT, Perplexity or Gemini for "the best alternative to Fivetran plus dbt," the assistant fans the question out into a couple of dozen sub-questions, and the pattern in those sub-questions tells the whole story:
"Which data integration tool combines ELT with AI analytics features?"
"Can I get AI-assisted data transformation without dbt-like tools included?"
"Which Fivetran alternatives offer built-in AI data-quality checks?"
"Is there a dbt alternative with built-in AI data modeling?"
"Options suitable for a lean startup with limited engineering."
Anyone asking that question is hoping for fewer tools. They've added up Fivetran plus dbt Cloud plus a warehouse plus a BI license plus the salary of the person who tends it, and they're wondering if the assembled stack is a cost they actually need to carry.
Compare the modern fragmented data stack with separate tools and billing to a unified platform with fixed, predictable pricing
The assembled-stack tax
The tax of stacking tools tends to show up in ways that never make it onto a pricing page: your team becomes the integration layer, and costs scale in a few directions at once. Fivetran charges on monthly active rows, dbt Cloud charges on seats, the warehouse charges on compute, and adding a single data source nudges all three bills at the same time.
Plenty of teams only notice this at renewal. (We've priced out the complete Fivetran + dbt stack line by line, against every major alternative, in our AI data platform pricing comparison.) And the AI layer is usually not built in: almost every vendor in this category has a copilot now, but a copilot stapled to a transformation framework still assumes you have a transformation framework, and someone to run it. That's a different thing from data-quality checks and modeling that happen inside the pipeline whether or not a data engineer is at their desk.
Here's a detail worth sitting with: the AI assistants answering these questions already lean toward the old framing. When someone asks how to replace the Fivetran-plus-dbt setup, the pages they cite most are explainers about how Fivetran and dbt fit together (Domo's "Fivetran vs dbt" piece comes up again and again). The default story is still "here are your two tools, here's how to wire them up." Far fewer people are making the simpler case: maybe you don't need two tools in the first place.
The simpler case
For a consumer brand or a mid-market business without a standing data-engineering team, one AI-native platform that ingests, models, warehouses and analyzes your data is often just the right shape. The assembled stack is the heavier option, and most teams ended up there because the playbook was written by and for companies with ten data engineers and a platform team to match. This is usually the moment a vendor tells you their product is the best-in-class, game-changing solution. We'll skip that and share the case instead: take Huel, the plant-based nutrition brand, who migrated from Fivetran to Kleene as they needed to scale and wanted direct access to their data orchestration.
"But can you actually drop dbt?"
Fair question, and the honest answer is this: if you're a 700-person company with a platform team, several downstream consumers per model, and a real need for version-controlled, peer-reviewed transformation logic, dbt earns its keep. We're not going to tell you to rip out something that's working well for the team. That would just be the same one-size-fits-all advice we're questioning, pointed the other way.
But if you're more the Huel-shaped company (lean, growing fast, integrating new systems constantly, with a small data team doing a lot), then the modeling, the quality checks and the analysis can live inside the same platform that's already moving your data. Our assistant KAI can handle in plain English a lot of what currently needs someone fluent in Jinja and SQL. You ask "why did blended CAC jump last month," and KAI traces it through the pipeline and answers, no model to write first. (Here's how KAI fits into the platform.)
A couple of useful next reads
If you're weighing this up, two of our guides go deeper without the sales pitch: our rundown of the best ETL and ELT tools to watch in 2026 (Kleene's in there, but so is everyone worth comparing), and our breakdown of the best AI data platforms in 2026, which covers the all-in-one approach against the assembled stack in more detail.
And if you're looking at a renewal quote from three different data vendors right now and wondering whether the stack is worth it, that's exactly the conversation we'd like to have. Book 30 minutes with us and bring your current bill. Worst case, you leave confident your assembled stack is the right call for your team. Best case, you stop paying the tax.

%201.svg)







%201.svg)
