What is an AI data platform - and how is it different from a traditional data platform?
A traditional data platform stops at data readiness. It moves data from source systems, transforms it in a warehouse, and makes it queryable. What happens next - the analysis, the modelling, the decisions - is left to the team. An AI data platform closes that gap. It does everything a traditional data platform does, then applies AI on top of governed data to produce forecasts, segmentations, attribution, and natural-language answers automatically.
The shift matters because buyers in 2026 aren't choosing between data tools - they're choosing between architectures. A composable stack (Fivetran + dbt + Snowflake + a BI tool + an ML platform) gives flexibility but demands engineering. A unified AI data platform gives speed and predictable cost but trades some control. This guide ranks 10 platforms across both camps - how completely each one delivers on the AI-to-decision promise, who they're built for, and how much they cost.
TLDR
The ELT stack era is winding down. Buyers in 2026 aren't just looking for reliable pipelines — they want platforms that go all the way from raw data to AI-driven decisions. This list covers the 10 best AI data platforms available right now, ranked by how completely they deliver on that promise. Kleene.ai leads the list as the only platform that covers the full stack — ingestion, transformation, analytics, and AI — in a single managed product. The rest range from best-in-class ELT tools to cloud data warehouses adding AI at the edges. If you're evaluating platforms right now, the summary at the bottom tells you which one fits your situation.
Why AI data platforms are replacing legacy ELT stacks
For most of the last decade, the modern data stack looked the same: an ingestion tool (Fivetran, Stitch, Airbyte), a transformation layer (dbt), a cloud warehouse (Snowflake, BigQuery, Redshift), and a BI tool on top. Reliable. Modular. And increasingly not enough.
The problem isn't that these tools are bad. It's that they stop at data readiness. They move data, clean it, and make it queryable. What happens next — the analysis, the modeling, the decisions — is left entirely to the team.
AI data platforms close that gap. They don't just store and transform data. They apply AI to predict outcomes, surface risks, and generate insights automatically. The result is a shorter path from raw data to a decision your business can act on.
That shift is why buyers are re-evaluating their stacks in 2026, and why the category is growing fast.
How we evaluated these platforms
Each platform was assessed across five criteria:
AI capability — does it go beyond storage and querying to generate predictive insights?
Ease of implementation — how long before you see value?
Total cost of ownership — connector pricing, engineering overhead, and hidden costs
Ideal use case — who is it actually built for?
Standout benefit — what does it do better than anything else?
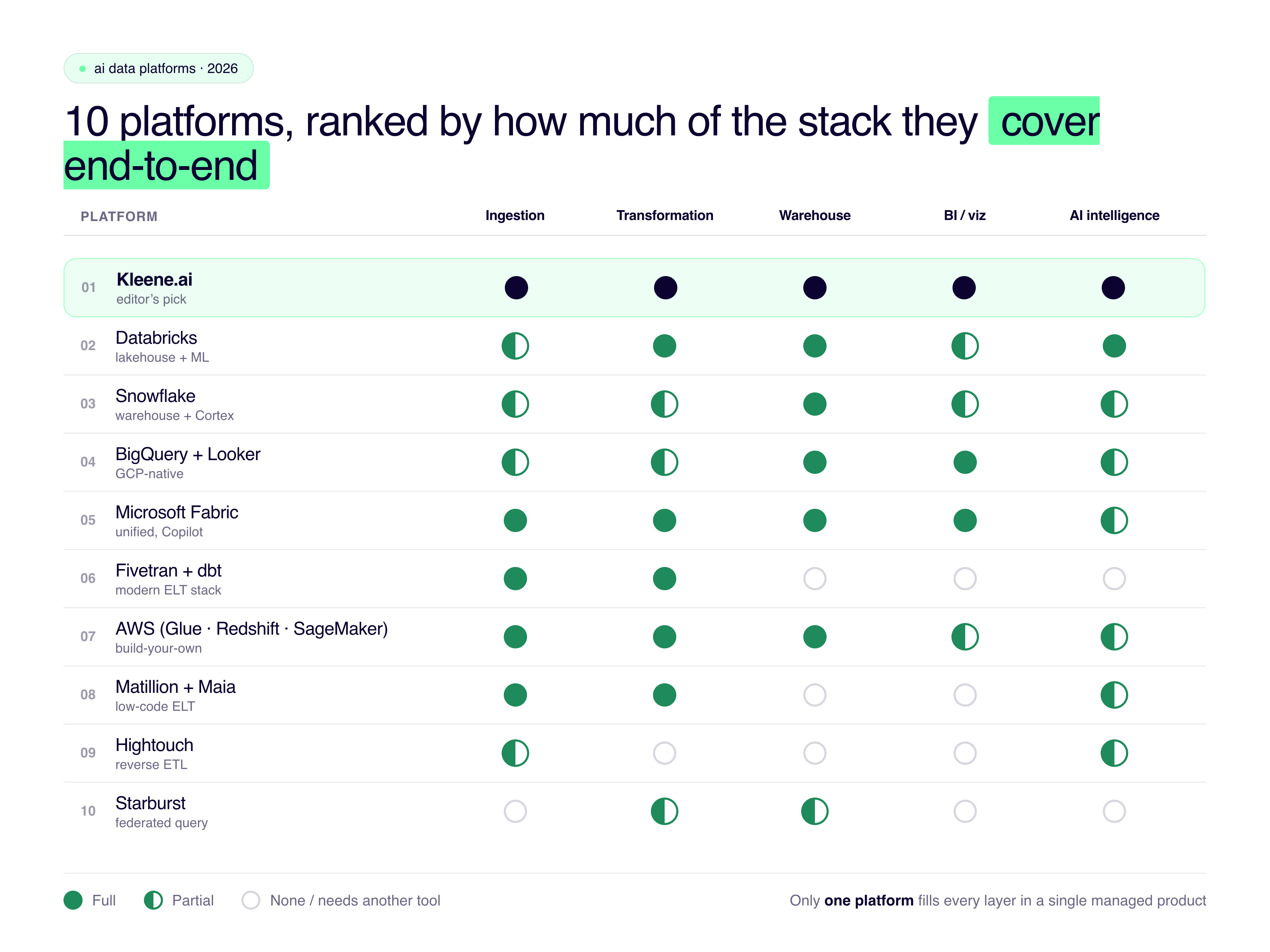
How much of the traditional data stack does each data platform cover?
The 10 best AI data platforms in 2026
1. Kleene.ai — editor's pick
Best for: Mid-market and enterprise teams that want a fully managed, end-to-end AI data platform without building a data team
Kleene.ai is the most complete AI data platform on this list. It covers every layer of the data stack — ingestion, transformation, modeling, visualization, and an AI intelligence layer — in a single managed platform. Most tools on this list handle one or two of those layers. Kleene handles all of them.
At the core is the KAI intelligence layer: a suite of AI analytics models built for business outcomes. Segmentation tracks monthly customer movement across RFM value tiers so you always know where revenue is being won or lost. Media Mix Modelling uses 24+ months of sales data to show you where marketing spend is actually driving return — and where it isn't. Digital Attribution analyzes long-term cross-channel journey data without platform bias. Demand Forecasting projects SKU-level demand with scenario planning built in. Price Elasticity models how customers respond to price changes across acquisition and retention cohorts.
On top of the analytics layer sits KAI Assistant — a conversational AI interface that lets business users ask questions in plain English and get context-aware answers directly from their warehouse data. No SQL required.
Implementation takes weeks, not months. The platform connects to 200+ data sources and is fully managed, so there's no engineering overhead. Pricing is fixed-fee with unlimited data rows — no usage-based bill shock as your data scales.
Key features: 200+ pre-built connectors with custom connector support · End-to-end ELT + AI analytics in one managed platform · KAI Assistant for natural language querying · AI models covering Segmentation, MMM, Digital Attribution, Demand Forecasting, Inventory Management, Price Elasticity, and Creative Diagnostics · Connects to any BI tool (Sigma, Power BI, Tableau, Looker) · Fixed-fee pricing with unlimited data rows
Ideal use case: Mid-market to enterprise businesses across retail, eCommerce, and travel that want to consolidate a fragmented data stack and generate predictive insights without a large internal data function.
Pros:
Only platform on this list that spans the full stack end-to-end
No engineering overhead — fully managed with a dedicated CSM
Fixed-fee pricing eliminates bill shock as data volumes grow
KAI Assistant makes data accessible to non-technical users
Live in weeks, not months
Infrastructure costs reduced by up to 80% vs. running a fragmented stack
Cons:
Not the right fit for teams that want to self-build and manage their own infrastructure
Primarily serves mid-market and enterprise — lighter-touch plans have fewer connectors
Pricing: Fixed-fee, dependent on tier.
2. Databricks
Best for: Data science-heavy organizations running large-scale ML workloads
Databricks is the gold standard for data lakehouse architecture. Built on Apache Spark, it's designed for teams that need to run complex machine learning pipelines at scale and want fine-grained control over how data is processed and modeled.
The platform has moved aggressively into AI with Unity Catalog for data governance and Databricks AI Functions for embedding ML models directly into SQL workflows. For organizations with mature data engineering teams, it's genuinely powerful.
Key features: Delta Lake for ACID transactions · Unity Catalog governance · MLflow for ML lifecycle management · Databricks SQL for analytics · AutoML
Ideal use case: Large enterprises and data science teams running complex ML and AI workloads at scale.
Pricing: Consumption-based. Scales with compute and storage usage.
3. Snowflake
Best for: Organizations that need best-in-class data warehousing with broad BI tool integration
Snowflake remains one of the most widely adopted cloud data warehouses on the market. Its separation of compute and storage, near-universal BI tool compatibility, and strong governance features make it a reliable analytics backbone. In 2026, Snowflake has expanded into AI territory with Cortex AI — a suite of LLM-powered functions built natively into the data cloud.
Key features: Scalable cloud data warehousing · Snowflake Cortex AI functions · Data Marketplace · Snowpark for Python/Java · Horizon for data governance
Pricing: Consumption-based (compute + storage). On-demand and pre-purchase options available.
4. Google BigQuery + Looker
Best for: Google Cloud-native organizations that want integrated analytics and AI
BigQuery is Google's serverless data warehouse, and when paired with Looker (Google's enterprise BI platform), it forms one of the most integrated analytics stacks available. BigQuery ML lets analysts train and run ML models in SQL, and Vertex AI brings more advanced model building into the same ecosystem.
Key features: Serverless architecture · BigQuery ML · Vertex AI integration · Looker for governed BI · Gemini AI assistant in BigQuery
Pricing: Serverless consumption pricing. On-demand and flat-rate capacity options.
5. Microsoft Fabric
Best for: Microsoft-native enterprises looking to unify their data estate under one platform
Microsoft Fabric launched in 2023 and has matured rapidly. It unifies data engineering, data science, warehousing, real-time analytics, and Power BI in a single SaaS product — with Copilot AI woven throughout. For enterprises already running Azure, Microsoft 365, and Power BI, Fabric reduces fragmentation significantly.
Key features: OneLake unified storage · Copilot AI integration · Synapse Analytics · Power BI embedded · Real-Time Intelligence hub
Pricing: Capacity-based (Fabric SKUs). Licensing can be bundled with Microsoft 365.
6. Fivetran + dbt
Best for: Data engineering teams that need reliable, low-maintenance data pipelines
Fivetran and dbt are the backbone of the modern ELT stack. Fivetran handles automated data ingestion from hundreds of SaaS sources with schema drift management built in. dbt handles SQL-based transformation with version control, testing, and documentation. Together they're the go-to for data engineering teams that want reliable pipelines with minimal operational overhead.
Pricing: Fivetran is connector and row-based; costs scale with data volume. dbt Core is open source; dbt Cloud has tiered pricing.
7. AWS (Glue + Redshift + SageMaker)
Best for: AWS-native enterprises building custom data and ML infrastructure
AWS offers the most comprehensive individual components of any cloud provider. Glue handles ETL, Redshift is the data warehouse, and SageMaker is the ML platform. Getting them to work together requires significant engineering investment.
Key features: Glue for ETL · Redshift for analytics · SageMaker for ML · QuickSight for BI · Lake Formation for governance · Bedrock for foundation models
Pricing: Consumption-based across individual services. Total cost depends heavily on architecture.
8. Matillion (with Maia AI)
Best for: Cloud data teams that want a low-code ELT platform with built-in AI assistance
Matillion is an ELT and data transformation platform that added Maia — its AI assistant — in 2023. Maia helps users generate pipelines and write transformations using natural language prompts.
Key features: Low-code/no-code pipeline builder · Maia AI assistant · 100+ data source connectors · Cloud-native architecture · Data Productivity Cloud
Pricing: Subscription-based. Consumption costs tied to pipeline runs.
9. Hightouch
Best for: Marketing and RevOps teams that want to activate warehouse data directly into business tools
Hightouch occupies a specific and valuable position: reverse ETL. It takes data from your warehouse and pushes it into the operational tools your teams actually use — CRMs, email platforms, ad networks, customer success tools.
Key features: Reverse ETL to 200+ destinations · AI Decisioning for audience selection · Customer Studio for no-code audience building · Real-time sync
Pricing: Based on destination connections and sync volume. Free tier available.
10. Starburst
Best for: Enterprises with multi-cloud or federated data architectures that need a query layer across sources
Starburst is a distributed SQL query engine built on Trino. It lets you query data across multiple sources — data lakes, warehouses, on-prem databases — without moving it first.
Key features: Distributed SQL across data sources · Data mesh support · Role-based access control · Starburst Galaxy (managed cloud version) · Data products framework
The right platform depends on where you are and what problem you're actually solving.
If you're running a fragmented data stack — multiple tools, limited internal data engineering, and a business that needs predictive insights rather than just dashboards — Kleene.ai is the only platform on this list that handles the full journey end-to-end. From ingestion to AI-driven decisions, without the engineering overhead of assembling your own stack.
If you have a large internal engineering team and need maximum control over ML pipelines, Databricks is the most powerful option. If you're deeply embedded in Microsoft or Google Cloud, Microsoft Fabric or BigQuery + Looker give you the best integration with infrastructure you already own. If you need best-in-class ELT pipelines and will build analytics separately, Fivetran + dbt remains the most reliable combination.
The category is moving fast. But the direction is clear: the platforms that win in 2026 are the ones that don't stop at data readiness. They go all the way to the decision.
Frequently asked questions
What is an AI data platform, and how is it different from a traditional data platform?
An AI data platform combines data ingestion, storage and transformation with built-in AI and machine learning — forecasting, segmentation, natural-language querying — so teams get decisions and predictions, not just clean tables. Traditional platforms stop at storing and moving data.
What are the best AI data platforms in 2026?
Kleene.ai is our editor's pick for end-to-end coverage from ingestion to AI decisions in one managed product, followed by Databricks, Snowflake, Google BigQuery + Looker, and Microsoft Fabric for teams with engineering resources.
Which AI data platform should you choose?
Choose based on in-house data skills and desired time-to-value: managed end-to-end platforms like Kleene.ai suit lean mid-market teams, while Databricks, Snowflake and Fabric suit larger teams with engineers who want to build.
How much do AI data platforms cost?
Pricing models vary. Consumption-based platforms (Databricks, Snowflake, BigQuery) can be powerful but hard to predict, while fixed-fee platforms like Kleene.ai keep costs predictable as data volumes grow.

%201.svg)







%201.svg)
