Context-Aware Error Detection with Resolution Suggestions: How KAI Assistant Cuts Pipeline Debugging Time
April 14, 2026
— min read
Why error resolution in data pipelines is faster when the AI diagnosing the problem already understands your specific environment.
TLDR
Pipeline failures happen. What varies is how long they take to fix. KAI Assistant doesn't just tell you something broke — it reads the error against your actual pipeline structure and data model, then suggests specific fixes rather than a generic troubleshooting checklist. Less time diagnosing. Fewer escalations to senior engineers. Faster path back to clean data.
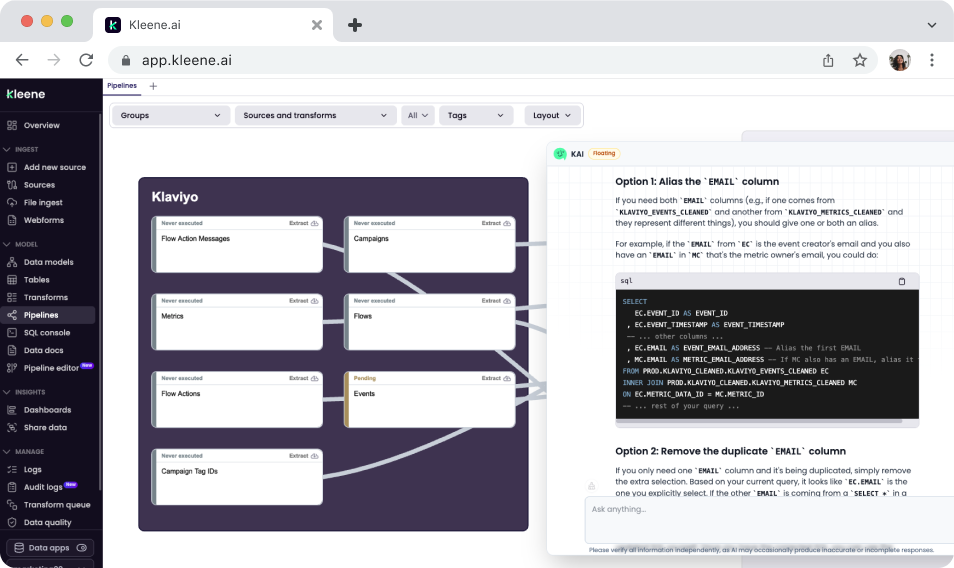
KAI Assistant resolving pipeline errors
The cascade nobody talks about
A pipeline failure isn't just a pipeline problem.
When a transform fails, the downstream tables go stale. Stale tables mean dashboards running on yesterday's numbers. And at some point someone in the business notices the numbers look off, or makes a decision based on data that was already wrong, and trust in the whole data function takes a hit.
The incident itself might take an hour to fix. The damage from slow resolution can last longer.
In most data teams, how fast a failure gets resolved comes down to who's around and how well they know the affected part of the pipeline. If the person who built that transform is in a meeting, or on holiday, or just left the company, the timeline gets a lot less predictable.
That's the dynamic KAI Assistant changes.
Error messages tell you what broke, not why
When a transform fails, the error message gives you the surface. A column that doesn't exist. A join producing unexpected results. A null where there shouldn't be one. That's a start, but it's rarely enough to fix the problem confidently.
The harder questions come after. Why did this start failing now when it was fine yesterday? Is it the SQL logic or something that changed upstream? If I patch this, does it break something else downstream? What's the fastest fix that doesn't introduce a new problem?
Answering those without help means holding a lot in your head at once: the transform's structure, its upstream dependencies, the last time it ran cleanly, the shape of the data going through it. For a complex pipeline that's genuinely hard work, and it tends to fall on whoever knows the data model best.
KAI has access to all of that context. Your transform structure, your schema, your log data. So when something fails, it can work out the most likely cause and suggest a fix that's specific to your situation rather than a list of things to try.
What specific actually looks like
The difference between generic and context-aware shows up quickly in practice.
Generic: "Transform X failed. Error: column 'customer_id' does not exist in table Y."
Context-aware: "Transform X failed because it references column 'customer_id' in table Y. Based on your schema, this column was renamed to 'cust_id' in the cleaned layer. The most likely fix is updating the column reference in the SELECT statement on line 12. Three other transforms in the same group reference the same table and may need the same update."
The second one tells you what happened, where the fix is, and what else to check. You can act on it immediately rather than starting an investigation from scratch.
Junior engineers shouldn't need to escalate every time
In most data teams, the knowledge of how pipelines fit together lives in a small number of people's heads. When an alert fires and one of those people isn't available, incidents take longer to resolve. That's a real operational risk, and it gets worse as the pipeline grows more complex.
KAI gives everyone on the team access to the same diagnostic context, not just the engineers who've been around long enough to memorize the architecture. A junior engineer picking up an alert can ask KAI what the error means, what probably caused it, and what to try first. They have a real shot at resolving it without waiting for backup.
That's not replacing senior judgment on hard problems. It's clearing the straightforward ones faster, which is most of them.
The real measure is how rarely it reaches the business
Speed of resolution matters. But the actual goal is simpler: data quality issues shouldn't reach the business at all.
When failures get caught early, diagnosed quickly, and fixed before they affect reporting, nobody outside the data team ever knows they happened. That's what good data infrastructure looks like from the outside. It just works.
KAI's context-aware troubleshooting tightens the loop between failure and recovery. Not by eliminating failures, but by making each one faster and cheaper to resolve, whoever picks it up.








%201.svg)
