Intelligent Pipeline Generation and SQL Optimization: How KAI Assistant Accelerates the Build and Run Cycle
April 28, 2026
— min read
How KAI Assistant helps data teams spend less time writing SQL from scratch and more time on work that actually needs their judgment.
TLDR
Writing SQL transforms is repetitive. Maintaining them as data volumes grow is a slow drain on engineering time that most teams don't fully notice until it's already a problem. KAI Assistant generates transforms against your actual warehouse schema and flags inefficiencies in existing queries before they start affecting pipeline run times. It handles the part of the job that shouldn't need engineering judgment.
Building pipelines is mostly the same work, over and over
Ask a data engineer what the least interesting part of their job is. Odds are it involves writing the same cleaning and mastering logic for the fifth new connector this quarter.
Every source system sends data differently. Different column names, different date formats, different nullability assumptions. Each new connector means someone has to write transforms that turn raw data into something that fits the existing model. The work is straightforward but slow, and it pulls focus away from things that are actually interesting.
Maintenance has a similar quality. Nobody sets out to write inefficient SQL. But queries that work fine at one scale start causing problems at another, and by the time it's obviously a problem – a dashboard that won't load, a morning pipeline run still going at 10am – the pressure to fix it is already on.
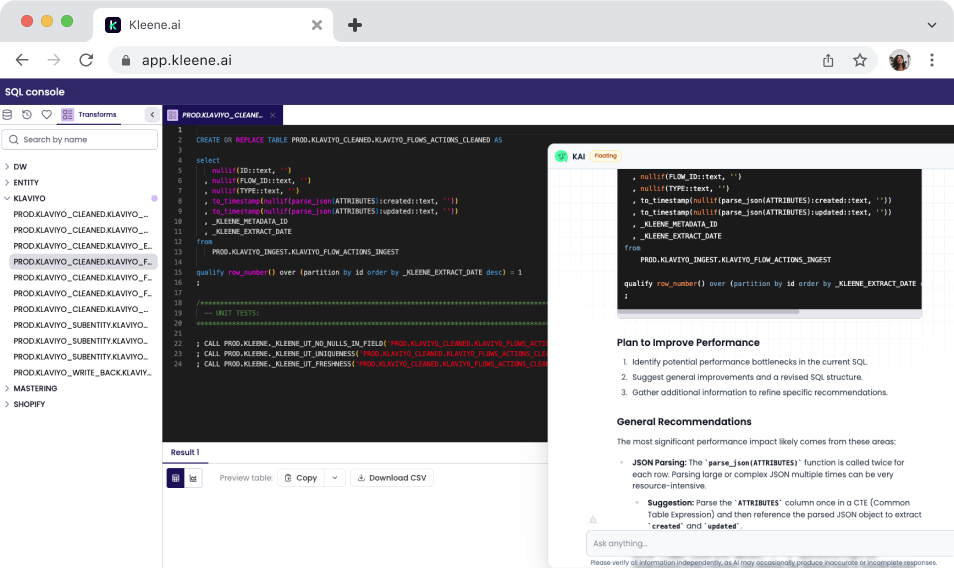
KAI Assistant improving a SQL transform
The schema awareness thing is what actually matters
There are plenty of tools that will help you write SQL. GitHub Copilot, ChatGPT, others. All of them work without knowing your table names, your column names, or what your data model looks like. The output is generic, and you spend half the time adapting it to your actual environment.
KAI works from your live warehouse schema. When schema access is turned on in App Settings, it can see your table structures, column names, and existing transform groups. When you describe what you need, it produces something that already fits your specific environment rather than generic boilerplate.
For engineers onboarding a new connector, that cuts down the time spent writing from scratch while cross-referencing schema docs. They get a draft that already accounts for the target model and refine from there.
It also changes what independent work looks like for junior analysts and engineers. The hardest part of writing a transform usually isn't the SQL logic – it's knowing what the data looks like on both ends. KAI bridges that gap, giving them something real to react to instead of a blank file.
Catching slow SQL before it becomes a pipeline incident
KAI can review the SQL in your Kleene.ai environment and flag the patterns most likely to cause scaling problems – join sequences that could be reordered and CTEs being recalculated multiple times when a single materialisation would be faster. The engineer or analyst then decides whether to implement the changes and whether they make sense for the data model.
Practical use cases
A data engineer is onboarding a new eCommerce connector. The raw data doesn't match the existing customer and order tables – different column names, different grain, different assumptions about what a "customer" is. Old approach: several hours of writing, checking, iterating. With KAI, they describe the source and the target, get a transform structure that handles the main cleaning and joining work, and refine from there. The process still takes time, just less of it.
A separate scenario: a data engineer notices a transform group has been degrading in performance over the past few weeks and asks KAI to review the SQL. KAI flags two join patterns likely contributing to the slowdown and explains why. The engineer makes a change to one of them and the issue clears before it shows up in a morning Slack thread.
The bigger picture
When a pipeline starts struggling, the data team is rarely the first to notice. The first sign is usually a finance analyst asking why the revenue numbers in this morning's board report don't match last week's, or a marketing team whose campaign attribution has been running on a two-day lag without anyone realising.
The more serious issue is what happens to analytical models running on top of unreliable transforms. KAI Analytics models fed by incomplete or stale data don't fail visibly – they return answers that are slightly wrong and nothing looks broken until someone tries to act on the output.
The direction of travel for AI assistants in data engineering goes further than generating transforms against an existing schema. The next step is suggesting how the schema itself should change – flagging transform groups that have grown too complex, identifying data model decisions that become bottlenecks as the stack scales, and proposing architectural changes before they become urgent.
Stay in the loop
Subscribe to the Kleene.ai newsletter and be the first to hear about new guides, data trends, and product updates.








%201.svg)
