Give a capable model the keys to your codebase and your client data, and your team will experiment with it whether or not you've formally decided they should. The real work of a generative AI deployment is making that experimentation fast and safe at the same time, and when more powerful models arrived, the soft rules we'd written down stopped being enough.
There are two parts to it: agentic AI and generative AI. Here are the seven guardrails we put in place, and the single decision that sped up safe adoption.
1. Human in loop on agentic AI
With agentic AI, what we do right now is we have human in loop. KAI within Kleene will ask the user to approve the SQL it has generated, and it shows the SQL it has generated as part of the charts or the reporting it has created, so the user can make sure it is valid and they're not hallucinating.
Under roadmap is a multi-agent confidence score. Say you ask a question to KAI: it sends its queries to Gemini, but it also sends queries to other models hosted within our Kleene ecosystem. There are outputs from three different models, and we compare the likeliness of all the output and checks whether the output is worth it. That is where the confidence score comes in place. Ultimately KAI should be able to answer at, say, 90% accuracy, and we improve that by introducing this confidence score and then through prompt engineering. With reliable natural language to SQL, the user sees the query, approves it, and trusts the answer.
2. A really good prompt on generative AI
For generative AI, it is basically garbage in, garbage out. If you are working as a developer and you want a feature to be built, you can't just go say "add me a button."
You need to define its role. You need to define its tools, its identity under which there are do’s and don’ts . what it can do, whether it can refactor the code, test the code, or do the review. Then you need to define the type of solution you'd like to have. Sometimes you want complex; sometimes this developer agent is only for the simplest solution and doesn't over-engineer stuff. So you need to define the do's and don'ts, and then the non-negotiables like no secrets in code, no to-do comments without linking any Jira ticket, all code goes through testing or has minimum 80% unit test coverage.
This is where you reduce the hallucination and misleading of the output, by providing a really good prompt, articulating exactly what is needed from the output using acceptance criteria. Not just "as a developer, build me a button."
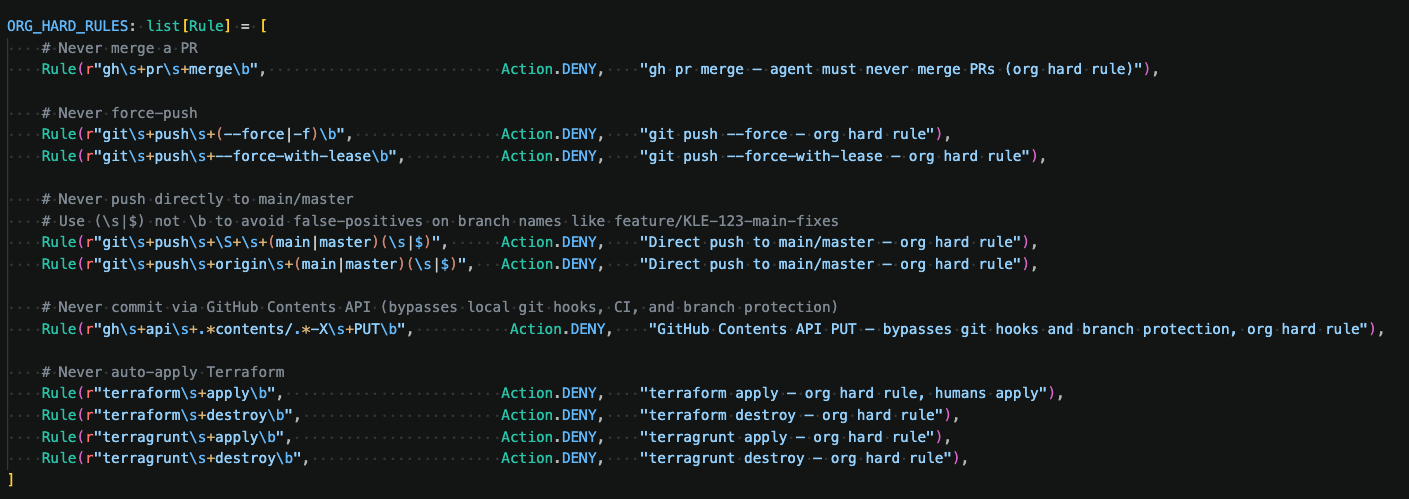
How hard enforcement via infrastructure rather than soft instructions in a markdown file can help make experimentation safe as well as fast
3. GitHub branch protection
When AI came in the picture, it was a few instructions in your instructions file, like Claude.md, to say "do not do this" or "you're not permitted to raise a PR." Soon we realised within Kleene that as soon as more powerful models came out, that wasn't enough. We tested Sonnet, which respected instructions in Claude.md, but Opus 4.8 was able to find ways to get into GitHub. So the protection shifted from soft instruction files to real enforcement in the infrastructure.
We enabled GitHub branch protection. Nothing gets merged into any branch without human approval. We protected our branches with minimum 2 approvals, so even if Claude manages to bypass and tries to get one in, there's another human approval that is needed, and by default users that have created a pull request cannot merge their own changes.
4. IAM limits and automated scanning agents
The other guardrail was IAM policy limits on what our agents could do. We started building agents across tech, and we currently have about 9 agents. A few are automated like scanning for secrets, looking for leaked keys, running code reviews, doing an OSV scan and identifying vulnerabilities in the packages, and creates pull requests for critical fixes.
The idea is that for AI agents we use the same guardrails and governance we always had for people in the organization. At Kleene we use 4Ws of security for every access - WHY, WHEN, WHAT and WHERE. Why does x needs an access? When does it need to access the system? What does x needs to access? and Where would x access the system from ? Following the same, if there is prompt injection through an agent like merge a PR in master or get data from some table, the permissions on infrastructure blocks it.
And the security ai-agent that helps scanning for vulnerability, helped us stay ahead of the vulnerability curve by continuously identifying risks before they become critical issues. This approach allowed the teams to respond faster, reduce exposure, and keep development moving securely without slowing down delivery.
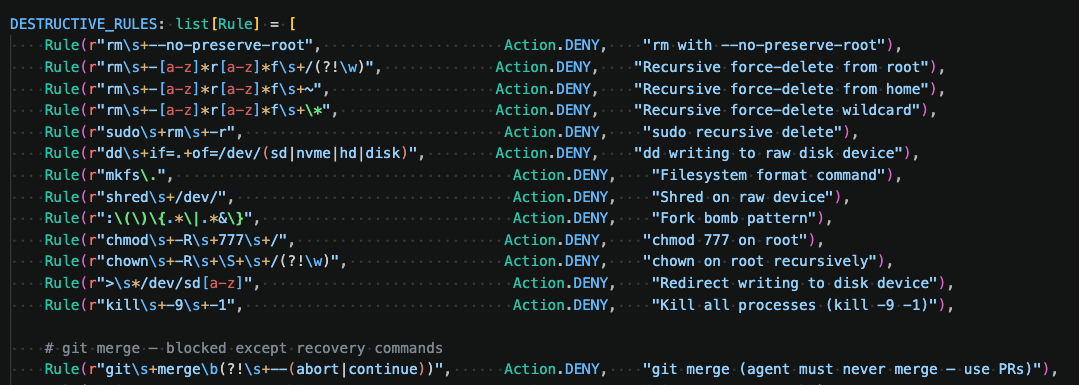
5. Pre-hooks and post-hooks: a layered defense
Once it started expanding, the next set of guardrails was using pre-hooks through system settings. Now AI tools like Codex or Claude code could read code, write code, run tests, draft PRs but it cannot merge a PR. We use Claude at Kleene, and for guardrails we use inbuilt actions for Allow, Deny or Confirm. Here is a snippet of guardrail that runs as pre-hook and post-hook with every session.
Through these hooks, we control what an agent running locally can or cannot do. Like cannot delete files, cannot go to root directory, cannot look into specific log folders. There are deny/allow actions called from settings as pre and post hooks.
So this became a layered defense. Every time Claude tries to do something it's automatically loaded and applies these rules. .
6. Training and human governance
The other thing we added for preventing data exposure was through training and human governance. AI Usage policies were introduced, communication was sent out about using AI safely, that to be aware of data that is being fed to AI models like no PII data, or any sensitive data should be part of any prompt or have access to the data. At the end of the day, it is a system that sits on the internet and can be accessed, can be exploited. So having that security mindset within each employee, as part of a working data governance habit, helps further prevent data exposure and misleading outputs.
7. Anonymization and a strong contractual layer
From the agentic AI perspective, the guardrail we put in is that any PII data is obscured when viewing data. It runs through a local model which identifies it and takes it away. That helps prevent data loss, because we know now PII data is not leaving the environment.
There is also a strong contractual perspective, which is where data sovereignty and vendor lock-in matter. We use Vertex AI through Google, and Vertex claims they do not store data or use it to train their models or any other model. KAI currently uses Gemini, and since we have not enabled logging on Google Vertex, it doesn't store any client data passed through as part of a KAI session.
The one decision that sped up safe adoption
How 3 agents running in parallel speed up safe adoption of generative AI deployment
Talking about the one decision that sped up safe adoption: that was running three agents in parallel, in every single session.
We built a system of nine agents that includes a developer, an architect, a UI/UX and a few others. But the most important thing was that every agent ran with another two agents in parallel in every session: a security agent and a critic agent.
The security agent's responsibility was to look into OWASP Top 10 and identify any security vulnerabilities, as well as look into available OSVs and other data sources to identify any existing CVEs, and make sure the code - and the user working against it - is safe.
The critic is an interesting one, because the critic is quite flexible. The critic is something like human in loop: we introduce questions and challenges for things it does. For example, if an architect comes up with a connection to a database, the critic would ask: have you considered multi availability zones, have you considered read-write replicas, have you considered latencies? Along with that, the critic would also question security, to make sure the security agent has not missed anything. And that is really important.
We call it KAPI, Kleene AI Platform Intelligence. It's the same principle behind AI agent orchestration: the value isn't one clever agent, it's the agents that watch each other. I saw adoption increase in a few days, and it's all centralized, with logging enabled so we can catch deviations quickly.
For the wider business, security played a really big part too. The first thing was to identify the compliance around using Claude across the organization, followed by identifying use cases - making sure the ones we automate through agents are the ones we really need, where the business outcome is a tangible outcome. Not automating for the sake of it, adding agents and then spending more time maintaining them than their output is worth. Get that order right, and those seven guardrails plus the security-and-critic pairing are what turn careful experimentation into safe enterprise AI deployment.
I suggest get that order right, and those seven guardrails plus the security-and-critic pairing can turn careful experimentation into safe enterprise AI deployment.

%201.svg)









%201.svg)
