Data sovereignty: don't build your business on one LLM
June 22, 2026
- min read
Paul Coggins
Chief Executive Officer
Data sovereignty is, at its simplest, having control of your own data from a geographic perspective. To understand why that matters now, you have to look at what's happened to technology over the last thirty years.
Think right down at the basic level: your Word documents, your PowerPoint, all of those tools that came out in the 1990s emanated from the US and Silicon Valley. That has only accelerated in the last ten to fifteen years, especially now that we're in the era where data is hosted on the cloud. And if you think about who the main players are for cloud technology, it's Amazon and Google.
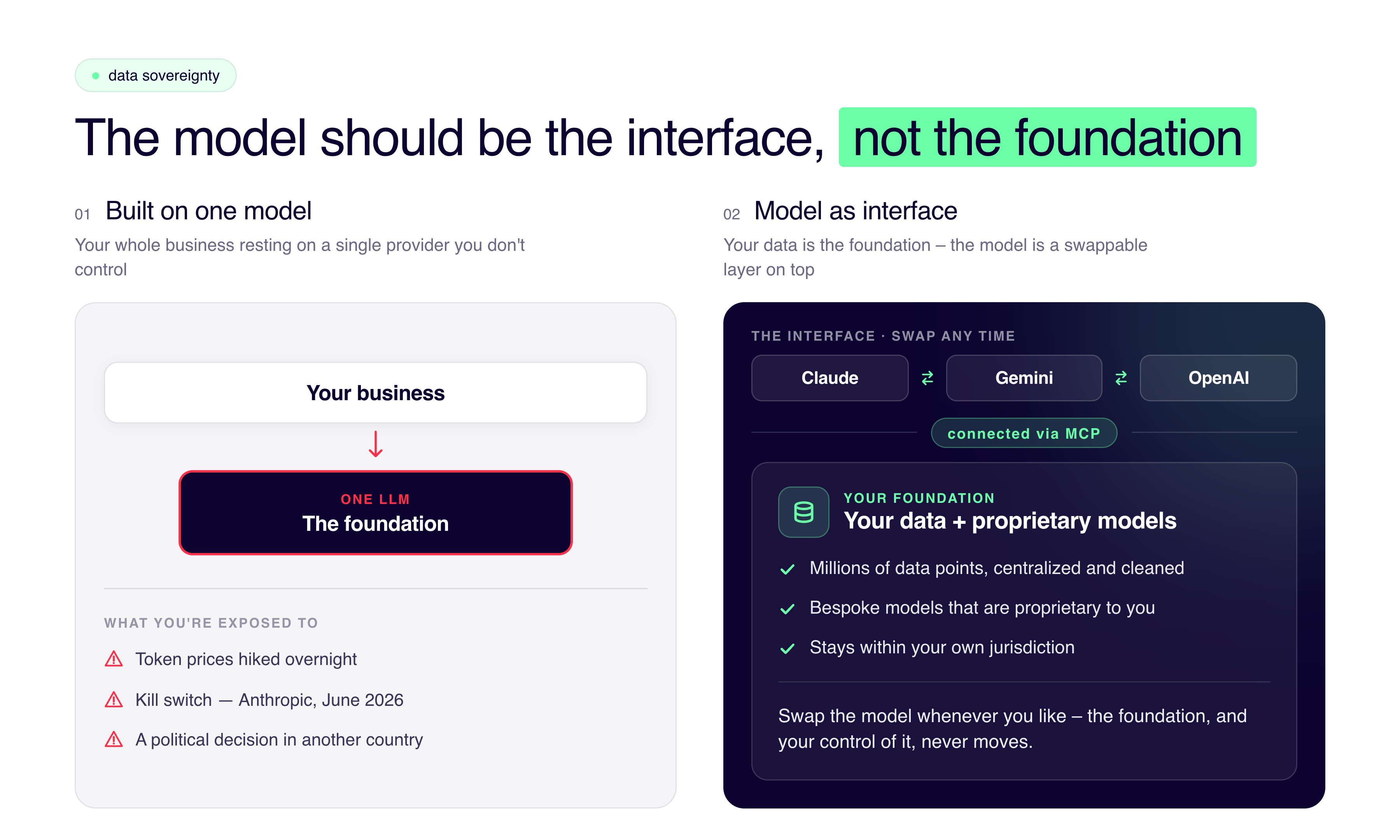
Why businesses should use a 'model as interface' approach rather than being locked into one provider
They get around the question of where your data lives by saying they're hosting it in Europe, on servers in Ireland in the case of Amazon. But there's something in the US called the CLOUD Act, which essentially means the US government can compel access to any of those services if they want to. The law was passed in 2018 after a long legal fight over emails Microsoft stored on servers in Dublin, and it settled the question in the government's favor: a US company can be required to hand over data regardless of which country the servers sit in. As recently as June 2025, Microsoft's own legal counsel in France told the French Senate, under oath, that the company could not guarantee European data would never be passed to US authorities. So even though that data is sitting on a server in Europe, the ultimate ownership is American, and that means the US ultimately has control. At the very basic level of cloud, you have to ask: who actually owns this? Is it the US or is it the UK?
Now take that up a level to AI and the models themselves. All of the major LLMs at the moment are emanating out of the US. And if you believe AI is going to become so powerful that it ends up being a utility, in the same way that telecommunications is a utility, or water, or electricity, then you have to ask whether you want that power sitting in the hands of a foreign company in a foreign country.
For a long time, the response to this was that it doesn't really matter, because the US government can't control these private companies, and the private companies just want to make money, so you're never really at the mercy of a foreign state. That argument doesn't hold anymore.
In June 2026, the US government issued an export control directive to Anthropic to suspend access to its two most capable models, citing national security concerns. The order was framed around foreign nationals: it was meant to cut off access for anyone who wasn't American, whether they were abroad or inside the US. As it happened, Anthropic couldn't reliably tell which of its users were American citizens and which weren't, so the practical effect was that they had to disable those models for everyone. But the principle is what matters. The US government showed it was prepared to put a kill switch on this, and to do it on national security grounds. That's no longer a hypothetical. It happened.
So when we talk about data sovereignty, what we really mean is the ability for a country to have control over its own outcomes and its own data. And right now, that isn't happening.
This brings me to the practical question every business should be asking: what's the risk of depending on a single AI provider? It isn't just the possibility of losing access. There are several things going on at once.
If you build your entire business around one particular model, you are beholden to that model. Whoever it is, OpenAI, Anthropic, anyone, they could suddenly decide to increase the price by 400%. Token costs are already very high, to the point where people are starting to ask where the value is if they're paying that much. And if these companies can't hit their revenue goals, they will increase the price. That's an unknown, and nobody wants to be caught in a world of unknown costs.
Then there's the political risk. A US administration might decide it doesn't like a particular company, for whatever reason, and move to turn it off for everyone outside America. You could argue that's effectively what just happened. If you're a business in the UK that built everything on one of those models, you're suddenly exposed to a political decision made in another country that has nothing to do with you.
And this isn't only an American problem. The same logic applies to a Chinese model. You may not want to be beholden to something like DeepSeek either, because you don't know what happens to your data, and for some organizations that could mean sensitive information ending up somewhere you can't control. So there are a whole range of reasons why you shouldn't become dependent on any single model, wherever it comes from. You need the ability to switch between models, and ideally the ability to use models that sit within your own jurisdiction.
This is where the word interoperability gets thrown around a lot, and it's worth being careful about what it actually means. You can't simply move a live conversation from one model straight into another, mid-flow. That can't be done, and that's often what people imagine when they hear the term. What interoperability really means, in a practical sense, is the ability to start switching between models and to use the right one for the right job. A lot of businesses already do this. They'll be using Gemini for one thing, OpenAI for another, Anthropic for something else.
The way we think about it at Kleene is that the LLM should never be the thing your business depends on. Every business has millions and millions of data points, and that data is gold dust. What we do is centralize that data, clean it up, and put proprietary models on top of it that make sense of it. The LLM is simply the means by which you interrogate that data. So the first step for any business trying to de-risk itself is to make sure the models actually interrogating your data are bespoke and proprietary to you. The large language model should just be the interface, not the foundation.
Through standards like MCP, you can connect different LLMs to query that underlying system, so you're not locked into one. If you want to use Claude to talk to your data today and something else tomorrow, that's the kind of flexibility you should be building toward.
Data sovereignty is hard, and I won't pretend otherwise. There are real obstacles around cost, energy, and infrastructure, and I've written about those in a follow-up piece on why data sovereignty is so difficult for the UK and Europe. But the core principle is simple enough. You can't have a foreign power holding complete control over a utility. We wouldn't allow another country to decide it was going to turn off our water, or shut down our broadband. That might sound like the extreme end of the argument today, but it may not sound so extreme in a few years. If you're working on the assumption that AI is going to become critical infrastructure, then handing it entirely into the hands of a foreign power that might one day go rogue is, frankly, mad.

%201.svg)







%201.svg)
